yolov8自定义识别物体
本文的文件夹名字命名以及格局都可以随意修改(前提是你懂整个逻辑)
新建一个文件夹kinda作为根目录
新建文件夹dataset存放标签和图片文件
dataset目录下新建image文件夹
image目录下新建train、val、test文件夹
不一定要全部建立,看个人需求
- train 训练数据
- val 验证数据
- test 测试数据
dataset目录下新建labels文件夹
labels目录下新建train、val、test文件夹
这几个文件夹后续用来存放volo格式标签数据文件。
kinda目录下新建dataset.yaml文件
文件数据格式如下
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes (80 COCO classes)
names:
0: person
1: bicycle
2: car
...
77: teddy bear
78: hair drier
79: toothbrush
创建标签
推荐图片标注工具[makesense]https://www.makesense.ai
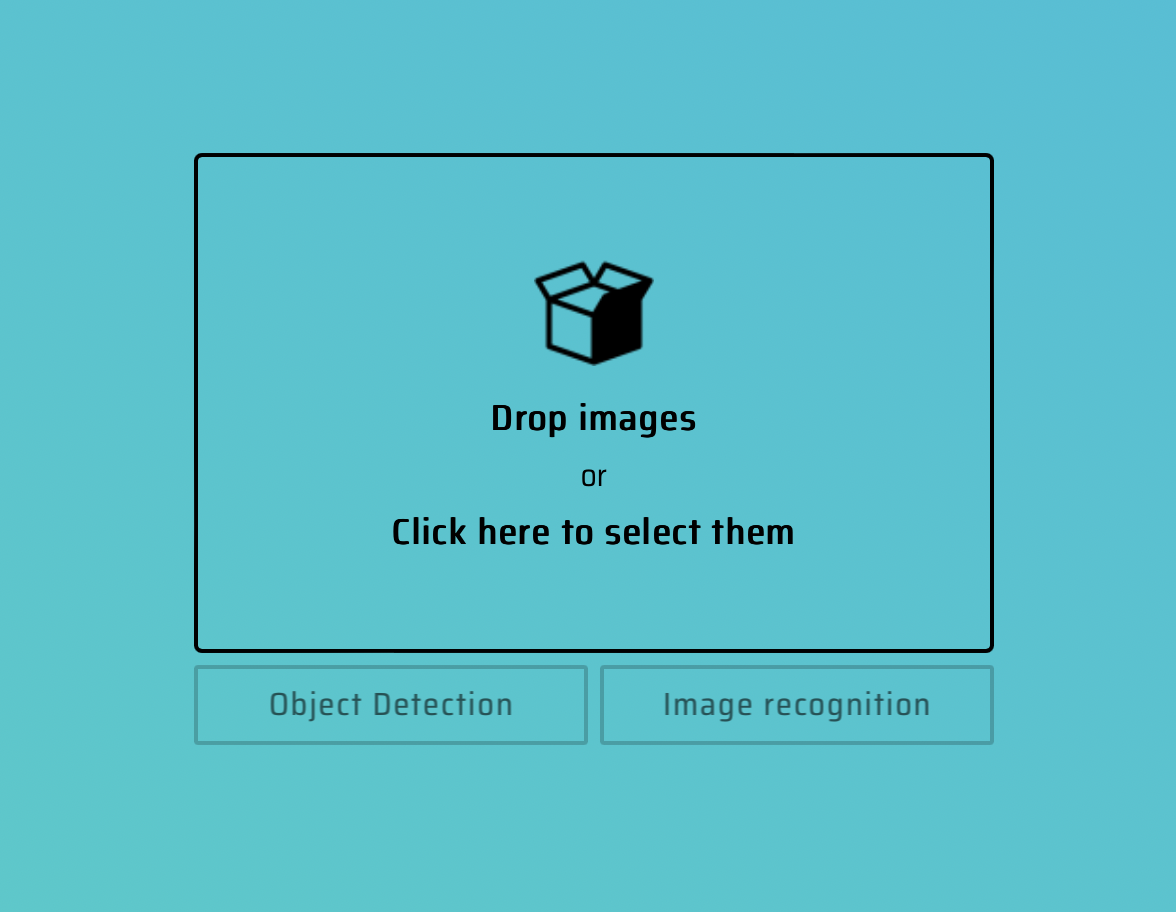
可以批量导入图片
如果是检测物体那么选择Object Detection,如果是图片分类任务那么选择Image recognition
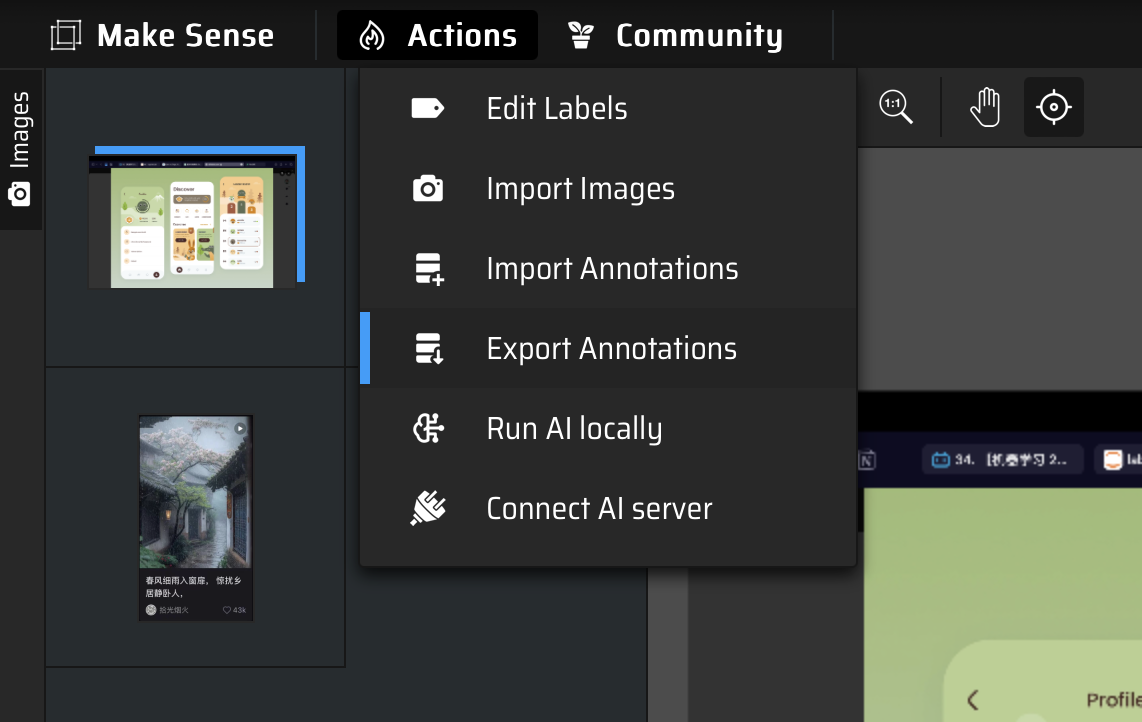
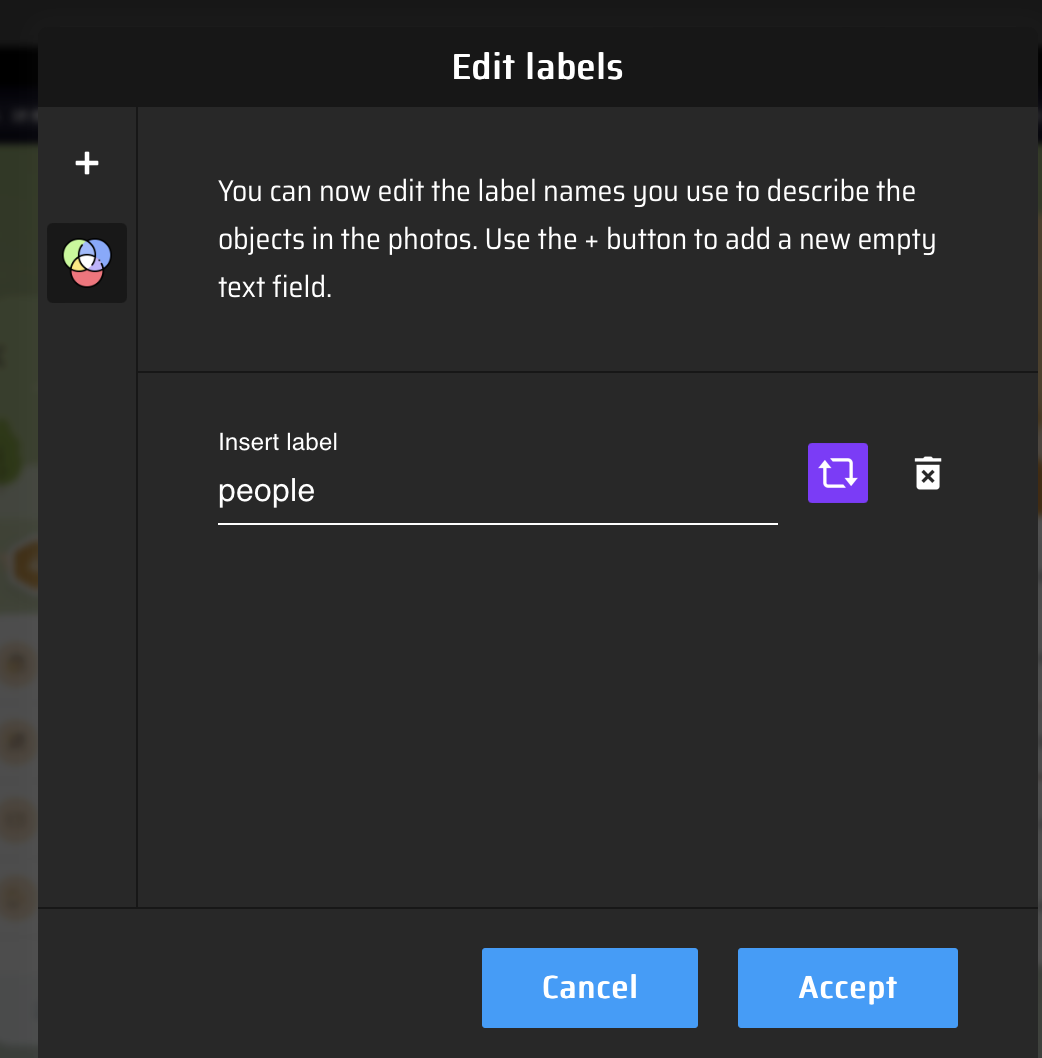
编辑标签
这一步可以先做,也可以随着绘制框线后续增加标签。
Edit Labels
绘制框线
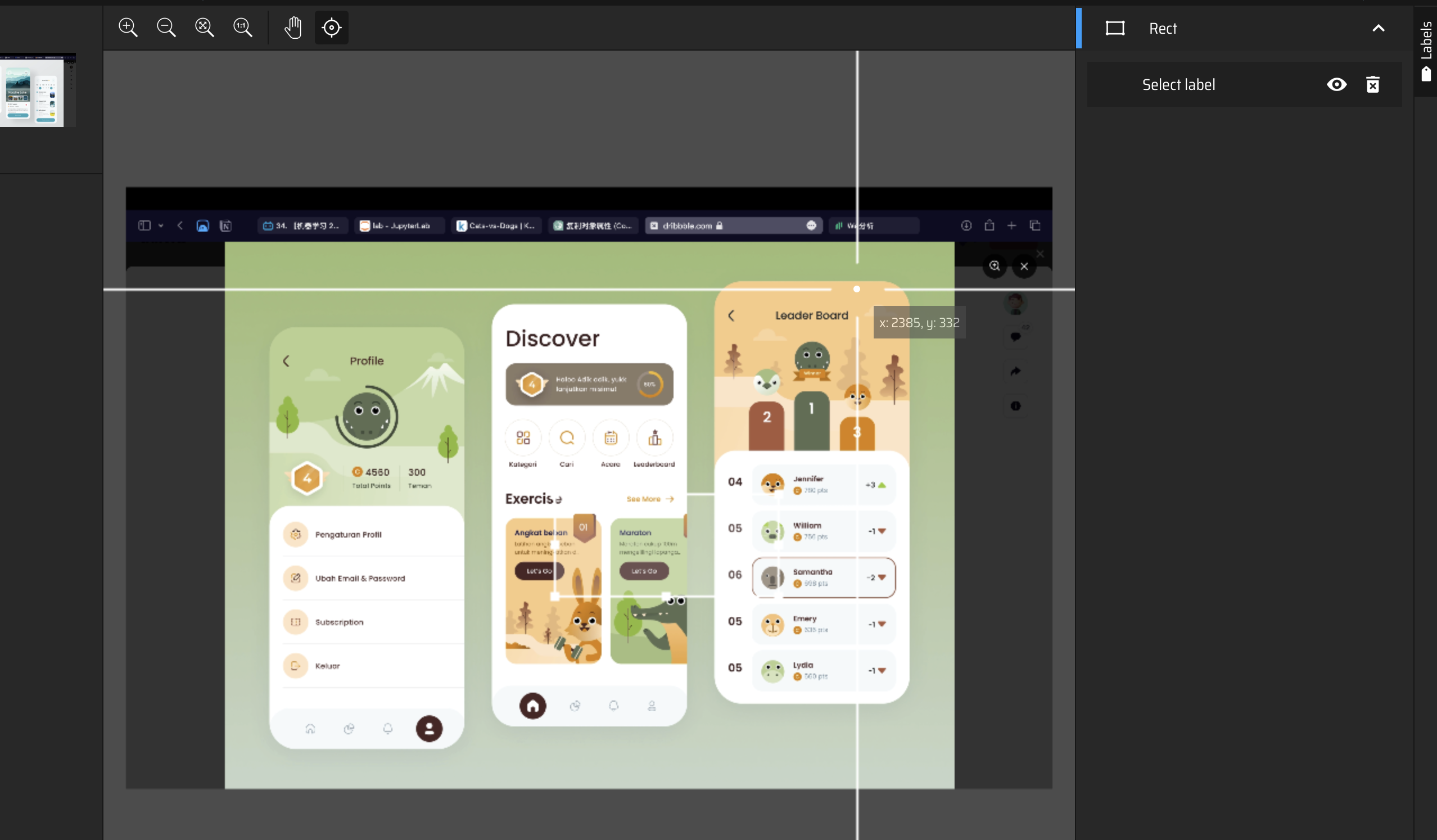
选择标签
导出yolo格式标注文件(txt格式)
Export Annotations
具体txt文件如下
0 0.481719 0.634028 0.690625 0.713278
0 0.741094 0.524306 0.314750 0.933389
27 0.364844 0.795833 0.078125 0.400000
最终文件夹结构如下
注意: 每张图片和其对应的label文件命名必须一致。
.
├── dataset.yaml
└── datasets
├── images
│ ├── train
│ │ ├── 01.jpg
│ │ ├── 02.jpg
│ │ ├── 03.jpg
│ │ └── 04.jpg
│ └── val
│ ├── 01.jpg
│ ├── 02.jpg
│ ├── 03.jpg
│ └── 04.jpg
└── labels
├── train
│ ├── 01.txt
│ ├── 02.txt
│ ├── 03.txt
│ └── 04.txt
├── train.cache
├── val
│ ├── 01.txt
│ ├── 02.txt
│ ├── 03.txt
│ └── 04.txt
└── val.cache
开始训练
from ultralytics import YOLO
# Create a new YOLO model from scratch
model = YOLO('yolov8n.yaml')
# Load a pretrained YOLO model (recommended for training)
model = YOLO('yolov8n.pt') # load an official model
# Train the model using the 'dataset.yaml' dataset for 3 epochs
results = model.train(data='dataset.yaml', epochs=3)
# Evaluate the model's performance on the validation set
results = model.val()
预测
# Predict with the model
results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
备注
可以通过如下方式关闭model函数的打印
results = model('https://ultralytics.com/images/bus.jpg', stream=False, verbose=False) # predict on an image
verbose这一参数表示是否显示内置的结果打印。stream这一参数用来决定是否使用cuda,如果是mac一般不开启,有n卡的情况下开启能极大的加速预测。
结果分析
上述model函数得到的结果如下
[ultralytics.yolo.engine.results.Results object with attributes:
_keys: ('boxes', 'masks', 'probs')
boxes: ultralytics.yolo.engine.results.Boxes object
keys: ['boxes']
masks: None
names: {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
orig_img: array([[[122, 148, 172],
[120, 146, 170],
[125, 153, 177],
...,
[157, 170, 184],
[158, 171, 185],
[158, 171, 185]],
[[127, 153, 177],
[124, 150, 174],
[127, 155, 179],
...,
[158, 171, 185],
[159, 172, 186],
[159, 172, 186]],
[[128, 154, 178],
[126, 152, 176],
[126, 154, 178],
...,
[158, 171, 185],
[158, 171, 185],
[158, 171, 185]],
...,
[[185, 185, 191],
[182, 182, 188],
[179, 179, 185],
...,
[114, 107, 112],
[115, 105, 111],
[116, 106, 112]],
[[157, 157, 163],
[180, 180, 186],
[185, 186, 190],
...,
[107, 97, 103],
[102, 92, 98],
[108, 98, 104]],
[[112, 112, 118],
[160, 160, 166],
[169, 170, 174],
...,
[ 99, 89, 95],
[ 96, 86, 92],
[102, 92, 98]]], dtype=uint8)
orig_shape: (1080, 810)
path: '/Users/kinda/Desktop/yolov8/bus.jpg'
probs: None
speed: {'preprocess': 0.5681514739990234, 'inference': 73.98080825805664, 'postprocess': 0.5743503570556641}]
results列表中的每一个对象都有如下参数
- _keys 结果字典中的键列表,包括 boxes(边界框)、masks(掩膜)和 probs(置信度)
- boxes 一个边界框对象,包含检测到的边界框的坐标、置信度和类别信息等。
- keys 一个掩膜对象,如果模型返回的是实例分割结果,则包含每个实例的掩膜信息。
- masks 一个置信度数组,如果模型返回的是分类结果,则包含每个类别的置信度值。
- names 一个类别名称字典,包含模型识别的每个类别的名称。
- orig_img 输入图像的原始像素矩阵。
- orig_shape 输入图像的原始尺寸。
- path 输入图像的文件路径或URL。
- probs 一个置信度数组,如果模型返回的是分类结果,则包含每个类别的置信度值。
- speed 一个字典,包含每个处理步骤的处理时间,包括 preprocess(预处理时间)、inference(推理时间)和 postprocess(后处理时间)。
其中的boxes又含有如下参数
- boxes:检测到的物体的边界框坐标,每个边界框都由左上角和右下角的坐标、置信度和类别标签组成。
- cls:每个边界框对应的类别标签。
- conf:每个边界框的置信度分数。
- data:与boxes属性相同,表示检测到的物体的边界框坐标、置信度和类别标签。
- id:未定义。
- is_track:是否为跟踪任务。
- orig_shape:原始图像的大小。
- shape:对象数据的大小。
- xywh:检测到的物体的边界框坐标,每个边界框都由中心坐标、宽度、高度和类别标签组成。
- xywhn:将xywh归一化到
[0,1]之间。 - xyxy:检测到的物体的边界框坐标,每个边界框都由左上角和右下角的坐标和类别标签组成。